02 纸上得来终觉浅(上)
文章内容基于redis6,本章节介绍了redis的实际应用,主要包含:大量键值对保存的案例场景,海量key时的聚合计算、排序计算、状态统计、基础统计的应用
大量键值对保存
场景案例
有这么一个需求场景,一个图片存储系统,图片的ID刚好可以对应和存储对象ID,所以采用了String类型来保存,键值的长度都是10位数。
刚开始,保存了大约1亿张图片,发现占用内存约6.4G。此时还算正常,当图片数量继续增加到2亿时开始出现由于要生成RDB而导致响应变慢了。
请问如何优化?
首先我们得找到变慢的原因,直接原因是RDB持久化文件太大所致
按道理来说,10位数整型无法存储,使用long型8个字节绝对够了,键值加一起也就16个字节;1个字节1B,16个字节16B;
1亿张图片为16亿B,约等于1.6G,为什么实际情况是6.4G?
那我们不禁要问,理论与实际为何相差这么大?
要回答这个问题,就需要对String的类型做个彻底的解剖。
疑团解析
之前介绍过Redis值中的String类型底层存储结构是简单动态字符串(SDS),其实它的存储结构如下:

比如上图中,key1和key2两个元素,它们都通过a、b、c三个无偏哈希函数进行计算落到不同的位置上,记为1。
当向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都位 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致(这就是误判)。
如果这个位数组比较大,错误率就会很低,如果这个位数组比较小,错误率就会比较大。当然位数组太大,所需要的hash函数就越多,会影响计算效率的。
我们发现为了存储已用长度、实际分配长度、结束符号信息需要额外的9个字节!比我们实际数据本身还要大。
这还没完,对于 String 类型来说,除了 SDS 的额外开销,还有一个来自于 RedisObject 结构体的开销。
因为 Redis 的数据类型有很多,而且,不同数据类型都有些相同的元数据要记录(比如最后一次访问的时间、被引用的次数等),所以,Redis 会用一个 RedisObject 结构体来统一记录这些元数据,同时指向实际数据。
一个 RedisObject 包含了 8 字节的元数据和一个 8 字节指针,这个指针再进一步指向具体数据类型的实际数据所在,当SDS是Int或Long类型时,指针就不需要了,指针位置可以直接存放数据,节省空间开销。
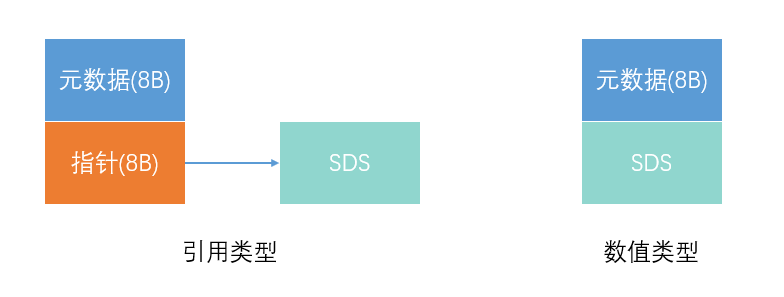
本场景中采用的是后一种:数值类型的。所以又额外多出来8个字节信息要存储。
但是好像加起来也不到64个字节呀?没错,这还没有完!因为在全局哈希表中,还要存储指针,entry值,链式指针
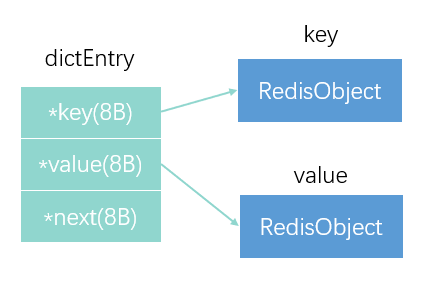
虽然三个指针只占了24个字节,但是Redis通常会多分配一些内存,一般往上按照2的幂次数取到32字节,以此来减少分配次数。
所以虽然数据本身只占了16个字节,但是还需要额外的48个字节存储其它信息。
这就是1亿个10位键值对真实存储情况。
优化手段
明白了简单动态字符串存储原理后,也理解了为什么1.6G的数据为什么占用了6.4G内存。那能换成哪种结构来节约内存呢?
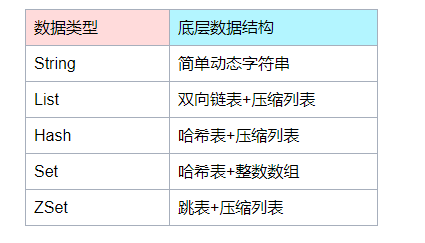
回顾下存储方式的底层数据结构,我们可以发现有个叫压缩列表的数据结构,它是一种非常节省内存的结构。
表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量,以及列表中的 entry 个数。压缩列表尾还有一个 zlend,表示列表结束。

- prev_len,表示前一个 entry 的长度。prev_len 有两种取值情况:1 字节或 5 字节。取值 1 字节时,表示上一个 entry 的长度小于 254 字节。虽然 1 字节的值能表示的数值范围是 0 到 255,但是压缩列表中 zlend 的取值默认是 255,因此,就默认用 255 表示整个压缩列表的结束,其他表示长度的地方就不能再用 255 这个值了。所以,当上一个 entry 长度小于 254 字节时,prev_len 取值为 1 字节,否则,就取值为 5 字节。
这些 entry 会挨个儿放置在内存中,不需要再用额外的指针进行连接,这样就可以节省指针所占用的空间。
在上述场景中每个对象大小都是固定的8字节,所以prev_len占1个字节,加上编码方式1字节,自身长度4字节,实际数据8字节,一个entry大约14字节就够了
String的额外开销最大的部分为dictEntry部分,大约占了32个字节,因为每一个键值对entry都对应一个dictEntry。而压缩列表将entey都按顺序放在一起,若干个entry只需要对应一个dictEntry,可以节省下许多额外的空间。
不过redis官方一直在优化各种数据结构的保存机制,不同的版本得到的值可能不太一样,大家千万不要拘泥与值的大小,而是通过存储机制的不同,选择适合的数据结构。这里有一个小工具,可以在线计算各种键值对长度和使用数据类型的内存消耗大小,在实际应用中一定要先测试下所用版本的真实情况,版本不同差别很大。
推荐的神奇小工具:Redis容量预估-极数云舟
海量keys统计
场景1 聚合计算
- 统计每天的新增用户数和第二天的留存用户数
需要系统中保存所有登录过的用户ID和每一天登录过的用户ID;所有登录过的用户ID可以使用Set来保存,key为user:id,value就是具体的userId值
每天的登录用户也可以使用SET来保存,不过需要有时间戳,可以把时间戳设计在key中,比如key设计为:user🆔20210202就表示2021年2月2号登录的用户ID集合
每天的新增用户,其实就是在当前的用户集合中把存在在累计用户集合中的用户剔除掉,所以只要用日用户Set与累计用户set做差集即可
第二天的留存用户,相当于在前一天的新增用户数还存在于当天的日用户Set中,很明显就是求二者的交集
场景2 排序计算
- 获取商品评论评论中的最新评论
出现最XXX的字眼时,我们很容易联想到包含了排序,所以使用ZSet方式存储,我们自己来决定每个元素的权重值,比如时间戳先后。
实现起来就很简单了,因为ZSet就是按照权重自动排序的,我们要做的就是使用命令直接来获取即可
比如:ZRANGEBYSCORE comments N-99 N 假设最新评论权重是N,那么这个语句就代表获取最新的100条评论
场景3 二值状态统计
- 统计一亿用户中连续10天打卡签到的数量
打卡的状态很有限,只有两种情况,要不打了,要不没打,所以我们称之为二值状态的统计问题。
在签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。
我们就可以选择Redis 提供的扩展数据类型 Bitmap ,它的底层数据结构实现其实也用String类型,我们可以把它看出是一个bit数组。
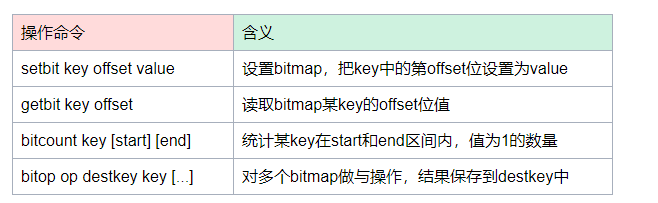
多少个1,就表示有多少个用户连续10天打卡签到。
有人看到有1亿位的bitmap是不是被吓了一跳,是不是担心内存开销过大,能存的下吗?我们尝试来计算下,1亿除以8转换为字节,然后除以1024转换为KB,再除以1024转换为MB,大约等于12,那么10天的数据也就占了120M的内存,如果再结合TTL的使用,及时释放掉不需要的签到记录,内存压力不算太大。
只要是能够转换为二值状态统计的问题,我们都可以使用bitmap去做,这样可以有效节省内存空间。
场景4 基数统计
- 统计1000个千万级访问量网页的UV
统计网页的UV我们需要进行去重操作,那么第一反应就是使用Set了,然后使用SCARD命令很方便就得到UV数了。
但是由于网页的访问量实在是打,是千万级别,那么一个Set就要记录千万个用户ID了,这样的页面有1000个,那内存消耗就有点大了。
我们再进一步思考,我们统计UV是否需要特别精准呢?一般是不需要特别精准的,只要差值别超过一个数量级,就有它的统计学意义了。
此时,我们可以使用Redis 提供的 HyperLogLog 了,是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。
在 Redis 中,每个 HyperLogLog 只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数。你看,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。
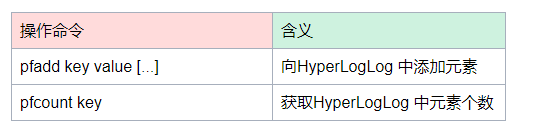
HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。
虽然误差率不算大,但是,如果你的业务场景需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型,计算好你需要的内存。
统计计算宝典
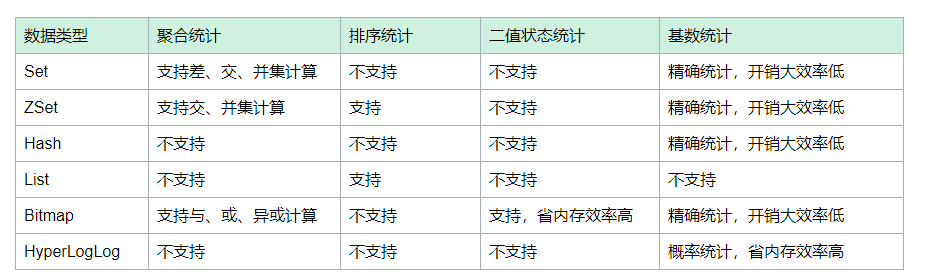
该表只是提供一些常规场景的思路和建议,并不能涵盖Redis各种统计场景,大家可以不断更新此表。